
HNM System for Prosodic Modification of Slovak Speech
Keywords
speech analysis, speech synthesis, HNM modeling, fundamental frequency
Introduction
Prosodic modifications of speech are needed for high-quality speech synthesis. Harmonic plus noise models are parametric models, and so it is easy to modify prosodic features like the intonation, stress or rhythm with good quality using these models.
Our system is based on the classical HNM model with some modifications that will be described below. The HNM model decomposes speech into a harmonic and non-harmonic part. Because the signal is decomposed into two parts, different modification methods can be applied to each part that can yield to more natural sounding pitch and time-scale modifications.
HNM model
A HNM model assumes that the speech signal is composed of a harmonic and a noise part. The harmonic part responds to the quasi-periodic components of the speech and the noise part responds to non-periodic components. These two components are separated in the frequency domain by a time-varying parameter called maximum voiced frequency Fm. The bandwidth up to Fm is represented by harmonic sinusoids and the bandwidth from Fm is represented by a modulated noise component. Unvoiced parts of speech are represented only by the noise part. The speech signal is obtained as a sum of the harmonic and the noise part s(t) = h(t) + n(t).
The harmonic part contains only harmonic multiplications of fundamental frequency. The signal is represented as a sum of sinusoids with corresponding frequencies, amplitudes and phases:
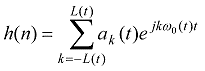 ,
,
where L(t) is the number of the harmonics, 0(t) is the fundamental frequency and ak(t) is the amplitude of the kth harmonic. There are three types of HNM models, we use the simplest HNM1 with constant amplitudes described before.
Noise partn(t) can be modeled in two different ways. The first way is by coding the spectral envelope using AR filter, where the synthesis is done by filtering white noise by the AR filter. The second way how to describe the spectral envelope is using the same method as for harmonic part. Since the noise part has no fundamental frequency, the F0 is set to 100 Hz. The phases of sinusoids are set randomly because the noise is a stochastic signal. This approach is used in our system, too.
Fig. 1. Analysis of the speech signal
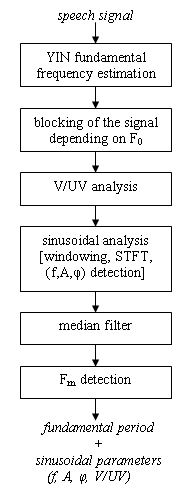
Fig. 2. Prosodic modification and synthesis of the speech signal
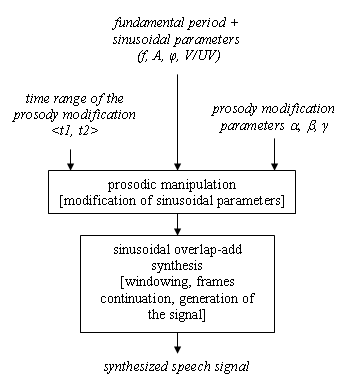
Fig.
3. Modified vowel ‘ú’.
a) original signal; b) synthetized signal; c) modified signal with
factors α=1.2 and β=1.3
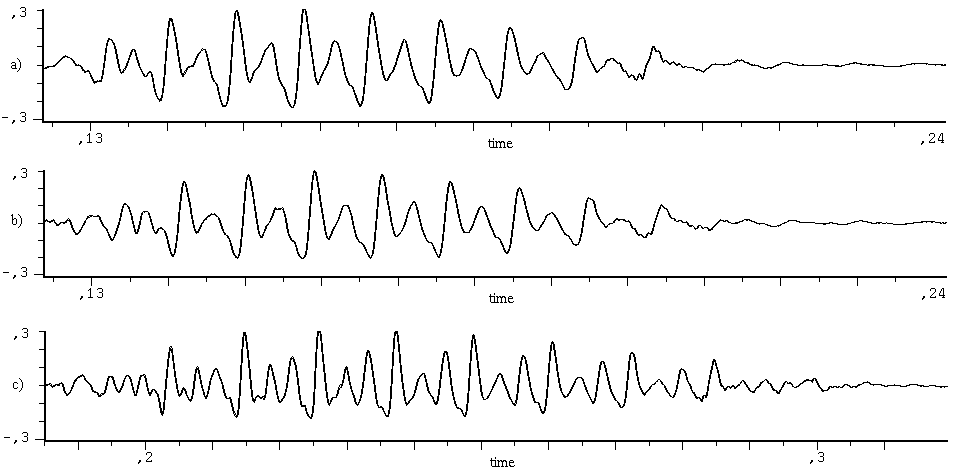
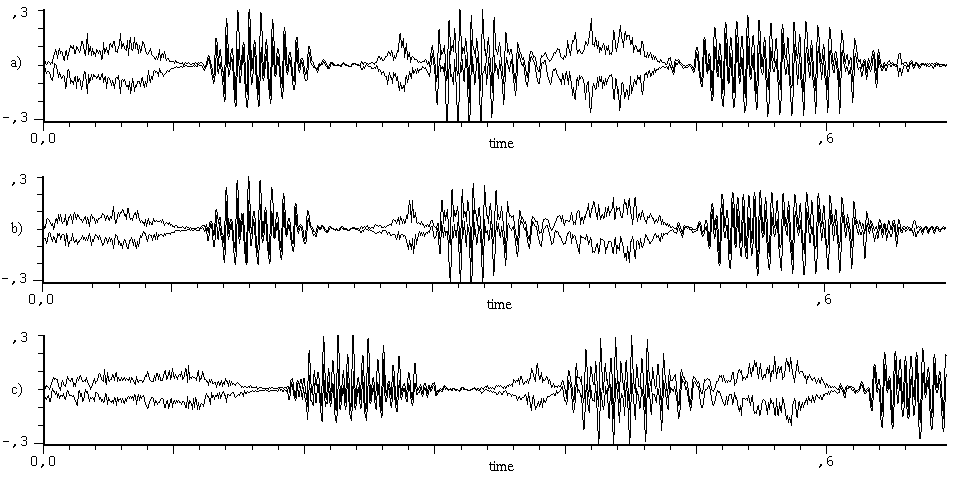
Fig. 4. Modified word‘súčasne’. The first syllable ‘sú’ is modified with factors α=1.2 and β=1.3 to add accent, the voiced part of the second syllable ‘čas’ is modified with factors α=1.05 and β=1.4 to emphasize the word. a) original signal; b) synthetized signal; c) modified signal
References
[1] Y. Stylianou, J. Laroche, E. Moulines, "High-Quality Speech Modification based on a Harmonic + Noise Model", EUROSPEECH, pp. 451–454, 1995
[2] Y. Stylianou, "Applying the harmonic plus noise model in concatenative speech synthesis," IEEE Trans. Speech and Audio Processing, Vol. 9, no. 1, January 2001, pp. 21--29,
[3] E. Moulines, F. Charpentier, "Pitch-synchronous waveform processing techniques for text-to-speech synthesis using diphones", Speech Communication, Vol. 9, 1990, pp. 453-467
[4] Y. Stylianou, "Harmonic plus Noise Models for Speech, combined with Statistical Methods, for Speech and Speaker Modification", PhD thesis, Ecole Nationale Superieure des Telecommunications, January 1996
[5] T. Virtanen, "Accurate Sinusoidal Model Analysis and Parameter Reduction by Fusion of Components ", AES 110th convention, Amsterdam, Netherlands, May 2001